Overthinking conference admin
At the moment I'm busy organising the EAMS 2022 conference. This is the fifth time the conference has run, and the third time fully online.
I'm pretty comfortable with what needs to happen now, and so far it seems to be going smoothly.
Over the years I've gradually automated more and more of the admin. I thought it might be interesting to write up what I've done.
This is very much a 'CLP knows how to write scripts to do things, so has done that' situation, rather than something I've done out of absolute necessity.
Do what works for you, I suppose!
Registrations and talk proposals
Talk proposals and attendee registrations are both managed through Newcastle University's home-built forms system. I thought since it's there, I should use it.
It's not too bad, but not certainly not great!
The main problem I have with it is that there's no API for getting responses, and it uses Shibboleth to handle authentication, so in order to get the responses I have to use a Firefox container tab to log in as the EAMS role account: there's no way of logging out of my personal account.
It's then four or five pages from the login page to download a CSV file of the responses.
Last year, I took to copying out the request as a curl command from Firefox's network tab and pasting that into a bash script - that lasted as long as the shibboleth session, which I think is a few hours.
It was still really awkward, and didn't help me when I had to process new registrations each morning of the conference.
This year, I've gone whole hog and written a Puppeteer script to go through the login process, then fetch the CSV.
Fortunately, the URL for the CSV file just depends on the form ID, so the scrpit isn't too complicated.
Here's the script:
2022/05/forms-puppeteer.js (Source)
import {USER, PASSWORD} from './config.mjs'; import puppeteer from 'puppeteer'; const FORM = process.argv[2]; (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto('https://forms.ncl.ac.uk'); await page.waitForSelector('#logincontainer'); await page.type('input[id="username"]', USER); await page.type('input[id="password"]', PASSWORD); await page.click('button[type="submit"]'); await page.waitForSelector('#seeyourforms'); const csv = await page.evaluate(async (FORM) => { const response = await fetch(`https://forms.ncl.ac.uk/export_entries.php?type=csv&form_id=${FORM}`, { method: 'GET', credentials: 'include' } ); const text = await response.text(); return text; }, FORM); console.log(csv); await browser.close(); })();
It takes the form ID from the command-line arguments, reads the username and password from a secret config file, then prints out the retrieved CSV to STDOUT.
Ideally the IT service would implement some kind of token-based authentication so I don't have to use Puppeteer, but I can't imagine it'd be high up their priority list, given everything else going on.
Putting the timetable together
Once I've fetched the CSV of the talk proposals form, there are a few jobs to do.
I have a Jupyter notebook to process the entries.
The first thing I do is produce an HTML summary of all the entries.
This uses a jinja template to produce a single HTML file, which I upload to the EAMS site for the other organisers to look at.
It contains each talk's speaker details, title, abstract, the preferred format for the talk, and any notes the submitter left.
2022/05/talks-html-jupyter.py (Source)
# ``year`` is the current year: datetime.datetime.now().year # ``talks`` is a list of processed form entries from jinja2 import Template, Environment, select_autoescape, pass_eval_context from markupsafe import Markup, escape from IPython.core.display import HTML import re env = Environment(autoescape=select_autoescape(['html', 'xml'])) _paragraph_re = re.compile(r'(?:\r\n|\r(?!\n)|\n){2,}') @pass_eval_context def nl2br(eval_ctx, value): result = u'\n\n'.join(u'<p>%s</p>' % p.replace('\n', Markup('<br>\n')) for p in _paragraph_re.split(jinja2.filters.escape(value))) result = re.sub(r'(https?[/\-.:a-zA-Z0-9_]+)',r'<a href="\1">\1</a>',result) if eval_ctx.autoescape: result = Markup(result) return result env.filters['br'] = nl2br template = env.from_string(""" <!doctype html> <html lang="en"> <head> <meta charset="utf-8"> <title>EAMS {{year}} talk submissions</title> <style> li { margin: 0.5em 0; } article { width: 40rem; margin: 5rem auto 0 auto; line-height: 1.5em; } </style> </head> <body> <h1>EAMS {{year}} talk submissions</h1> <ul> {% for talk in talks %} <li><a href="#talk-{{loop.index}}">{{talk.title}}</a></li> {% endfor %} </ul> {% for talk in talks %} <article id="talk-{{loop.index}}"> <h1 style="font-size: 1.2em; font-weight: bold">{{talk.title|br}}</h1> <p>{{talk.names|br}}</p> <p><a href="mailto:{{talk.email}}">{{talk.email}}</a></p> <p style="font-style: italic">{{talk.format}}</p> <p>{{talk.timezone}}</p> <p>{{talk.description|br}}</p> {% if talk.notes %}<p><strong>Notes:</strong> {{talk.notes|br}}</p>{% endif %} </article> {% endfor %} </body> </html>""") h = template.render(year=year, talks=sorted(talks,key=lambda t: re.sub(r'\W','',t['title'].lower()))) with open('talks.html','w') as f: f.write(h)
Then I set up a Miro board to schedule the talks.

The EAMS schedule in a Miro board.
I created a grid representing the sessions, then made sticky notes for each of the talks, colour coded by the desired format.
(Fortunately there are few enough formats that I could pick colours I can differentiate! One small annoyance in Miro is that the colour picker doesn't label the colours, and it's hard to copy a colour from one object to another - you have to press the "Add colour" button and use the eyedropper.)
I also stuck smaller sticky notes on each talk with any constraints: some speakers can only do certain days, or because of their time zone can only make one session in a day.
I really like Miro!
It's really easy to move things around and arrange them in groups.
Once the organising committee had agreed on a timetable, I need to put it online.
The conference website
The conference website, eams.ncl.ac.uk, is a static site made with Hugo.
I picked Hugo a few years ago just to try it out.
I like the way content can be structured, but I spend more time trying to work out how to use the templating system than actually using it.
It feels like all the difficult syntax of LISP, with none of the useful features of LISP.
I don't know Go, but it feels like a lot of awkwardness around how the template language works stems from not doing anything clever on top of Go's very strict type system.
Anyway, the site is built, and I've stuck with it for a few years.
Each talk is a separate markdown file in a sessions folder, with a subfolder for each year.
Hugo groups these automatically, producing a programme page for each year.
After I've added the time of each talk to my Jupyter notebook, it creates these files.
I usually have to do a few small edits like tidying up paragraph breaks and fixing typos.
For past years, my Hugo theme produces an alphabetical listing of the talks, with thumbnails, linking to pages where you can see the abstract, supporting files or links, and the video recording.
For the current year, it shows a day-by-day plan.
This year, I've added a table, which makes it easier to get an overview of the whole conference.
Because there's already a vertical listing, I didn't try to make the table responsive - it's just hidden on narrower screens.
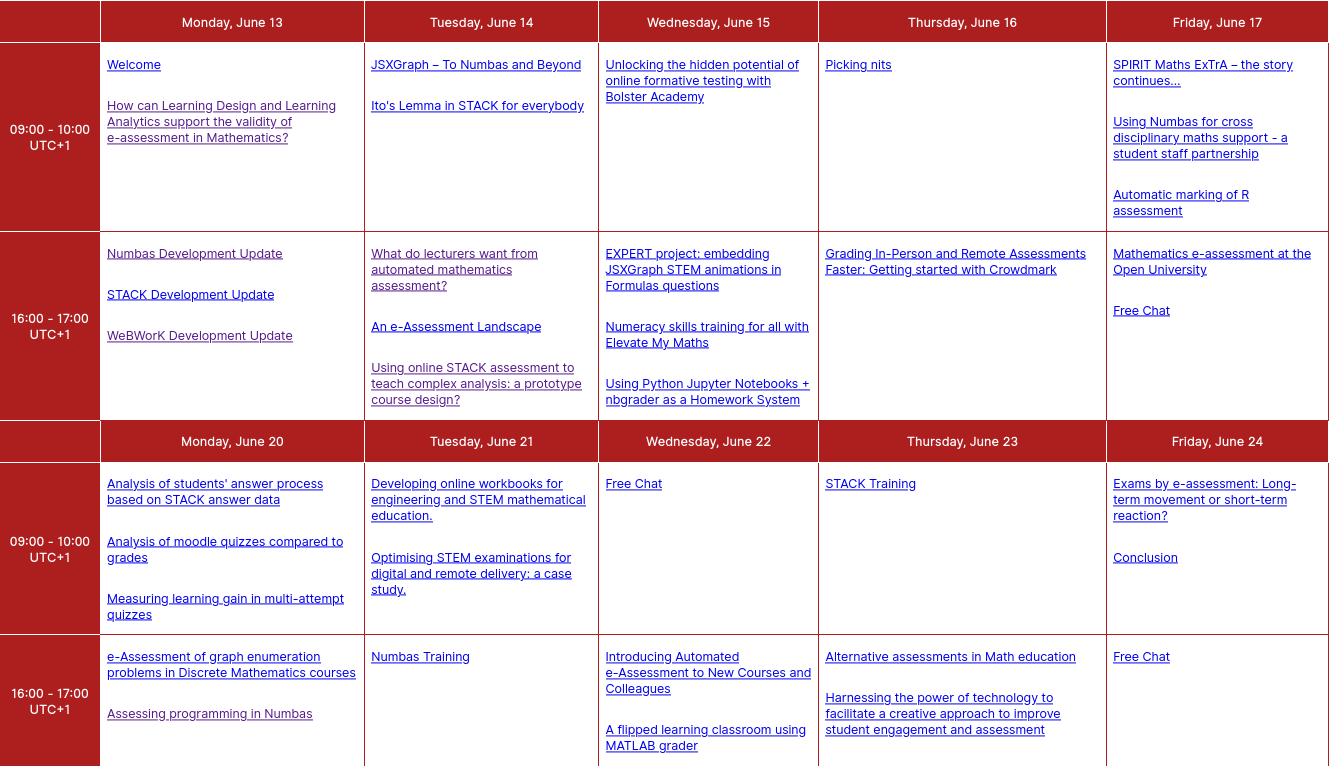
The table view of the EAMS 2022 programme.
I also have a separate page which produces a slideshow of the programme, using reveal.js. We show this at the start and end of each session, to show what's coming up.

The slideshow view of the EAMS 2022 programme.
Changes to the programme happen all the time, so I think it really is useful to have all of this automated.
I wish that I could automate updating the corresponding bits of the conference Moodle, but that is definitely a time sink!
Each talk needs a thumbnail image, which is shown both on the site and on the conference's YouTube channel.
In previous years I spent a lot of time taking screenshots of slides, or of the recording. It was quite finicky: I often had to remove bits of the surrounding interface, and sometimes accidentally ended up with a couple of pixels of black border around the thumbnails.
This year I've written a script to extract the first slide from a PDF using pdftoppm, so the thumbnails are produced automatically.
It means that I have to wait for speakers to send me their slides, but should be a net saving in time and should produce more consistent thumbnails.
Here's my script:
2022/05/eams-make_thumbnails.py (Source)
from pathlib import Path from datetime import datetime import subprocess year = datetime.now().year sessions = Path('content','sessions',str(year)) for p in sessions.iterdir(): if p.is_dir(): thumbnail = p / 'thumbnail.png' if thumbnail.exists(): continue pdfs = [f for f in p.iterdir() if f.suffix == '.pdf'] if not pdfs: continue pdf = pdfs[0] print(f"Making thumbnail for {p}") subprocess.run(['pdftoppm',pdf,str(thumbnail.with_suffix('')),'-png','-f','1','-singlefile'])
Handling attendees
I have another Jupyter notebook for processing attendee registrations.
Again, I use Puppeteer to fetch the CSV from the forms site.
I do a little bit of analysis: I look at the TLDs of each attendee's email address, to get an idea of where in the world they're coming from. This year, it looks like about a third of attendees are from the UK.
Every year there are a handful of people who make a typo in the email field, so I have a couple of cells for finding and fixing those.
When the conference starts I need to email everyone the joining instructions, so I have a cell to print out all the addresses in a format that can be pasted directly into Outlook's BCC field:
You wouldn't believe the number of people that sign up to give a talk at a conference, then don't register to attend. I suppose it's fair to assume that I've already got their email address in one form, so I should register them automatically.
This breaks down when there's more than one speaker, and I only have one contact email address.
There are also important questions about consent for recording and accessibility accommodations in the attendee form that speakers should fill in.
So I read in the talks CSV file, and look for names that don't match anything in the attendance list. I can then email those people and ask them to register as attendees.
Finally, the form has a question "What are you hoping to get out of EAMS?", with free-text response.
I use a jinja template to produce an HTML summary of the responses to this question, like I do for the talk submissions.
The Moodle environment
All of the interaction that attendees have happens through a Moodle site.
So my Jupyter notebook produces a CSV file in the format that Moodle enjoys:
2022/05/eams-attendee-upload.py (Source)
import pandas as pd from trans import trans import re def make_username(name): return trans(re.sub(r'\W','',name).lower()) def fix_person(d): names = d['alternatename'].split(' ') d['firstname'] = names[0] d['lastname'] = ' '.join(names[1:]) d['username'] = make_username(d['alternatename']) return d import csv import re fields = { 'alternatename': 'Your name', 'institution': 'Your affiliation', 'email': 'Your email address', } people = [] def load_file(filename,last_name=None): people = [] with open(filename) as f: r = csv.DictReader(f) for row in r: d = {k:row[fields[k]] for k in fields.keys()} fix_person(d) if last_name is not None and d['lastname'].lower()==last_name.lower(): break people.append(d) return people fieldnames = ['alternatename', 'institution', 'email', 'firstname', 'lastname', 'username','cohort1'] def output_people(people,filename): with open(filename,'w') as f: w = csv.DictWriter(f,fieldnames=fieldnames) w.writeheader() for p in people: p['cohort1'] = f'participants{year}' w.writerow(p) last_uploaded_name = None # The name of the last person I uploaded, so I produce a CSV file only containing new people since then new_people = load_file(FORM_FILE,last_uploaded_name) output_people(new_people,'user-upload.csv')
On Moodle, I use cohorts to auto-enrol everyone in each of the courses for this year's conference.
Before the conference starts I do a big upload of everyone that's registered so far, and then I do another upload each day.
Because this is largely automated, it means I can make sure people are usually able to attend the next live session after they register.
It would be lovely to have it fully automated, though!